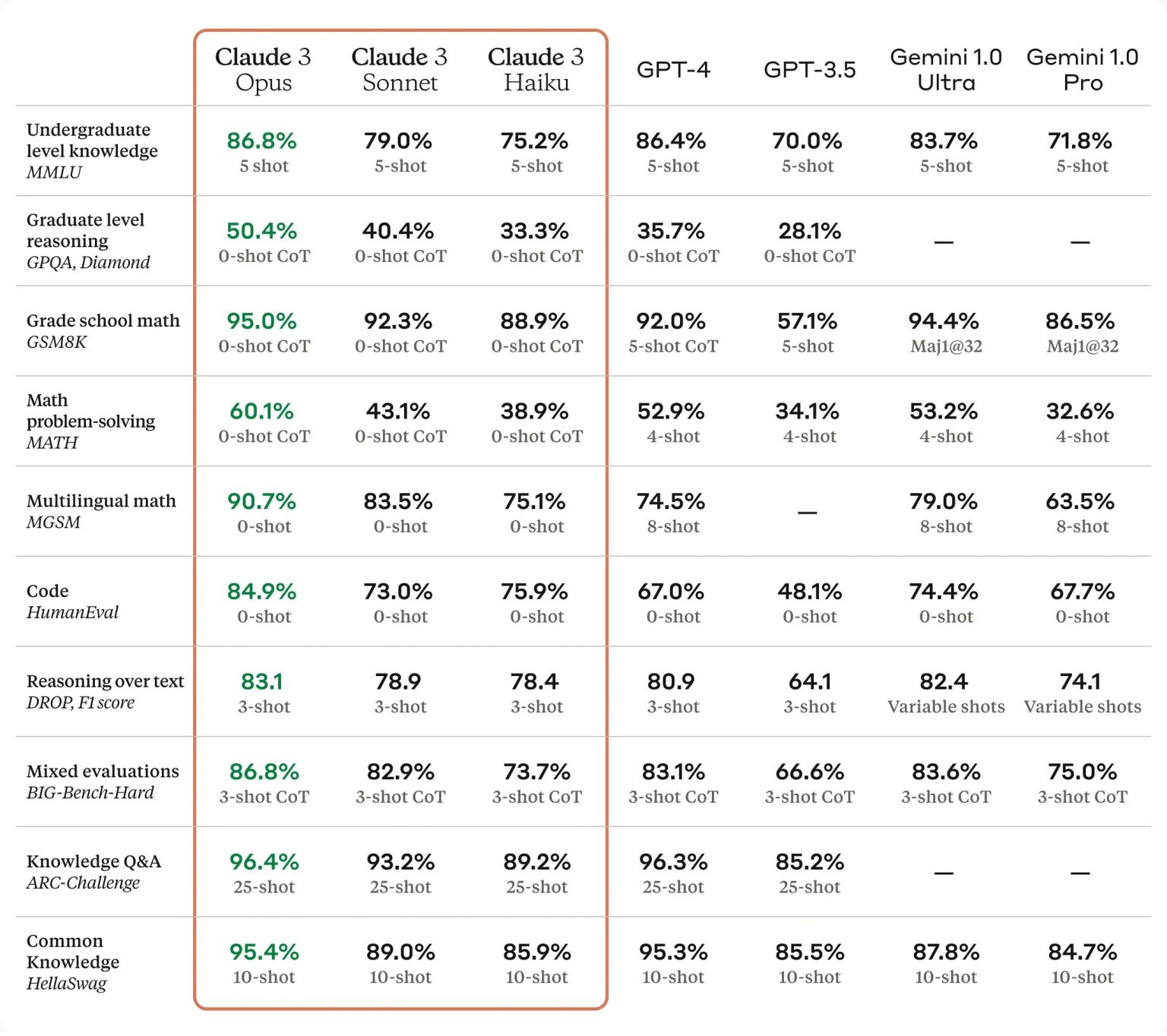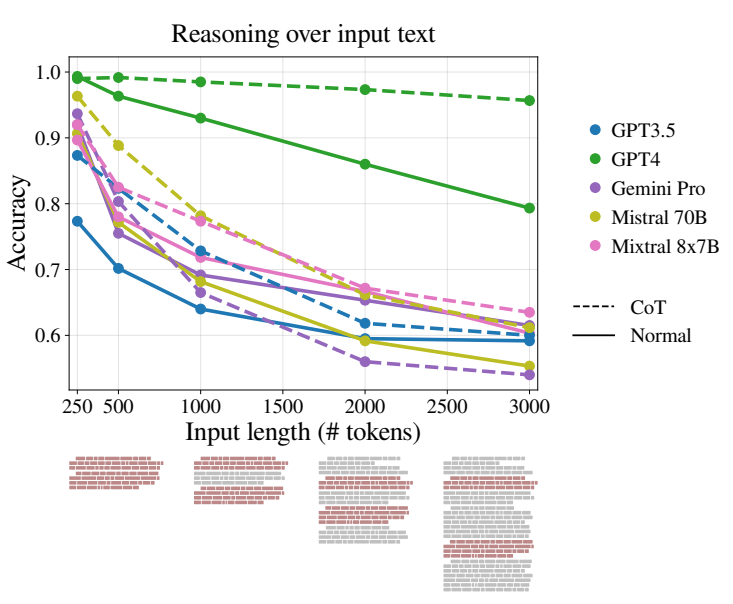
Despite their rapid advancement, large language models (LLMs) have a surprising weakness: they struggle to handle longer inputs effectively. This new study, conducted by researchers at Bar-Ilan University and the Allen Institute for AI, sheds light on this critical limitation.
Key Findings:
- Performance Decline: The study found a significant decline in LLMs' reasoning abilities as the length of the input text increases. This was observed across different datasets and model architectures, suggesting a systemic issue rather than isolated cases.
- Irrelevant Information Overload: Even irrelevant padding within the input can hinder LLM performance, indicating that filtering out noise is a major challenge for these models. Duplicating relevant information within the padding didn't improve performance, suggesting the issue goes beyond simply identifying irrelevant content.
- Ignoring Instructions: As input length grows, LLMs tend to disregard instructions provided within the text. They may even generate responses suggesting they lack sufficient information, despite having everything needed to answer the question correctly.
- Bias Creep: The study found an alarming increase in bias towards answering "False" as input length increased. This suggests potential issues with probability estimation or decision-making within the models, possibly stemming from uncertainty caused by longer inputs or biases present in the training data.
Implications:
These findings raise concerns about the reliability and fairness of LLMs, especially in applications requiring accurate reasoning and unbiased decision-making. The study highlights the need for:
- Robust Bias Detection and Mitigation: Implementing strategies to identify and reduce biases during model training and fine-tuning can help ensure fair and impartial outputs.
- Diverse Training Data: Utilizing diverse and balanced datasets that represent a wide range of scenarios can help minimize biases and improve model generalization.
- Further Research: This study adds to the growing body of research highlighting fundamental limitations in LLMs. Continued exploration is crucial to address these issues and ensure the integrity and functionality of these models over time.
This research emphasizes the importance of being cautious when relying on LLMs, particularly for tasks involving long inputs, complex reasoning, and critical decision-making. Continued research and development are crucial to address these limitations and ensure the responsible and effective use of LLMs in various applications.